Pacheco RL, Martimbianco ALC, Riera, R. Medidas de tamanho de efeito. 2023. Disponível em: www.nepsbeats.com.
Última atualização: 23/abril/2024.
Continuaremos analisando um ensaio clínico randomizado que possui o seguinte PICO:
P: participantes com Covid-19 grave
I: “covidina”
C: placebo
O: mortalidade em 28 dias e tempo de internação
A hipótese principal do estudo é a de que a covidina reduziria a mortalidade e o tempo de internação dos pacientes com Covid-19 em 28 dias, podendo ser utilizada no tratamento de pacientes graves. No total, o ensaio clínico recrutou 200 participantes para o grupo covidina e 200 participantes para o grupo placebo.
Base 1. Base de dados do ensaio clínico randomizado que avaliou a covidina para Covid-19 grave.
Code
knitr::kable(df[1:10, ], )
id
group
age
days_hosp
died
35
1
Placebo
57
21
Dead
394
2
Intervention
24
9
Alive
178
3
Placebo
90
15
Dead
78
4
Placebo
18
17
Alive
378
5
Intervention
85
14
Alive
57
6
Placebo
77
16
Alive
82
7
Placebo
61
14
Dead
274
8
Intervention
72
7
Alive
316
9
Intervention
72
13
Alive
95
10
Placebo
71
22
Alive
Tabela 1. Tabela de contingência do ensaio clínico randomizado que avaliou a covidina para Covid-19 grave.
Morto
Vivo
Total
Covidina
55
(27.5%)
145
(72.5%)
200
(100%)
Placebo
114
(57%)
86
(43%)
200
(100%)
Pela tabela de contingência, observamos que o risco relativo do estudo é 0,48 e o odds ratio é 0,29.
Generalizando os resultados do estudo para a população
O risco relativo e o odds ratio calculados são as estimativas pontuais do estudo que descrevem o que aconteceu com os 400 prticipantes do ensaio clínico em questão.
No entanto, estamos interessados em utilizar os dados desta amostra para extrapolar a conclusão para a “população”. Em um ensaio clínico randomizado, a população pode ser assumida como os pacientes que serão tratados na prática e que possuem características semelhantes aos participantes do estudo.
Uma das formas de fazer esses processos inferenciais é por meio de testes de hipótese. Podemos realizar um teste Chi².
Code
chisq.test(df$died, df$group, correct =FALSE)
Pearson's Chi-squared test
data: df$died and df$group
X-squared = 35.667, df = 1, p-value = 2.341e-09
O valor de p identificado é muito pequeno (Pr = 2.341e-09 = 0.000000002341) e frequentemente seria considerado como estatisticamente significante pelo autor do estudo. A interpretação é a de que podemos afastar a hipótese nula com segurança, ou de que estamos confiantes de que haja algum efeito na redução de mortalidade com o uso da intervenção na população.
Apesar de frequente, os testes de hipótese levam para outra pergunta intuitiva: qual é a magnitude de efeito compatível com o uso da intervenção?
O intervalo de confiança é uma medida inferencial que pode ser interpretada como um intervalo de valores compatíveis com o efeito da intervenção na população. A análise a seguir apresenta o intervalo de confiança do risco relativo e o intervalo de confiança do odds ratio.
[1] "The risk in the intervention group is = 0.275"
[1] "The risk in the control group is = 0.57"
[1] "The relative risk is = 0.48 (95% Confidence Interval = 0.37 to 0.62)"
[1] "The risk difference is = -0.29 (95% Confidence Interval = -0.38 to -0.2)"
[1] "The odds ratio is = 0.29 (95% Confidence Interval = 0.19 to 0.44)"
[1] "The chi-squared value is = 35.667"
[1] "The p-value is = 2.341e-09"
Os resultados deste estudo poderiam ser descritos das seguintes formas:
Risco relativo = 0.48; IC95% = 0.37 a 0.62; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de risco de 38% a 63% com o uso da intervenção.
Odds ratio = 0.29; IC95% = 0.19 a 0.44; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de odds de 56% a 81% com o uso da intervenção.
Ambos os resultados são válidos, e a interpretação deve levar em conta se o odds ratio ou o risco relativo foram calculados.
A maior limitação dos testes de hipótese, como o Chi², é que eles não podem ser ajustados por variáveis consideradas importantes pelos pesquisadores do estudo. Com base na análise anterior, estimou-se o seguinte resultado:
Odds ratio = 0.29; IC95% = 0.19 a 0.44; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de odds de 56% a 81% com o uso da intervenção.
Uma outra forma de calcular o resultado seria pela utilização de regressão logística ou algum outro modelo generalizado.
Code
library(tidyverse)df <- df %>%mutate(died_num =ifelse(died =="Dead", 1, 0))df <- df %>%mutate(group_num =ifelse(group =="Intervention", 1, 0))reg_logistica <-glm(died_num ~ group_num, data = df, family ="binomial"(link ="logit"))summary(reg_logistica)or <-exp(coef(reg_logistica))ci <-exp(confint(reg_logistica))orci# Output is omitted
O resultado da análise de regressão não ajustada é o mesmo odds ratio calculado (considerando mínimas diferenças de arredondamento e fórmulas).
Também pode-se chegar ao mesmo risco relativo calculado anteriormente por meio de um modelo linear generalizado (risco relativo = 0.48; IC95% = 0.37 a 0.62; p = 0.0000).
Code
library(risks)fit_rr <-riskratio(formula = died_num ~ group_num, data = df, approach ="glm")summary(fit_rr)rr <-exp(coef(fit_rr))ci_rr <-exp(confint(fit_rr))rrci_rr# Output is omitted
Análises ajustadas vs. não ajustadas
Os modelos de regressão apresentados podem ser ajustados por variáveis consideradas importantes pelos autores do estudo.
O código a seguir demonstra a análise de regressão logística ajustada pela idade.
Code
library(tidyverse)reg_logistica <-glm(died_num ~ group_num + age, data = df, family ="binomial"(link ="logit"))summary(reg_logistica)or <-exp(coef(reg_logistica))ci <-exp(confint(reg_logistica))orci# Output is omitted
Neste caso, o resultado da análise ajustada foi similar ao da análise não-ajustada.
O estudo poderia relatar a seguinte informação:
Odds ratio ajustado pela idade = 0.286; IC95% = 0.187 a 0.433; p = 0.0000).
Este ajuste também poderia ser realizado no modelo linear utilizado para o cálculo do risco relativo. Ainda, mais de uma variável pode ser considerada para a realização do ajuste, como por exemplo o sexo.
A escolha das variáveis a serem utilizadas é um passo muito importante no planejamento da análise estatística, e deve levar em conta o conhecimento prévio sobre a doença e estudos anteriores na área.
Análises ajustadas podem ser motivo de debate ao interpretar o resultado de estudos clínicos, pois dependendo das variáveis utilizadas no modelo os resultados podem ser diferentes. Nem sempre os especialistas concordam sobre os ajustes realizados e em muitos casos a escolha das variáveis de um modelo é baseada em critérios inadequados.
No caso em análise, a estimativa do odds ratio e seu intervalo de confiança são ligeiramente diferentes da análise não-ajustada, mas a conclusão geral deve ser a mesma nesse exemplo: estamos confiantes que é esperado um efeito importante na redução de mortalidade para a população que receberá a intervenção na prática.
Cuidado ao inspecionar intervalos de confiança
A figura abaixo apresenta o intervalo de confiança de sete estudos cujo desfecho principal é uma diferença de médias entre duas intervenções.
Code
ci_from_p <-function(p, delta, type ="DIFF") {if (type =="DIFF") { z <--0.862+sqrt(0.743-2.404*log(p)) se <-abs(delta / z) ci_limit <- se*1.96 ci_lower <- delta - ci_limit ci_upper <- delta + ci_limitreturn(c(ci_lower, ci_upper, se, delta)) } if(type =="RATIO") { z <--0.862+sqrt(0.743-2.404*log(p)) est <-log(delta) se <-abs(est / z) ci_limit <- se*1.96 ci_lower <-exp(est - ci_limit) ci_upper <-exp(est + ci_limit) log_se <-log(se) log_delta <-log(delta)return(c(ci_lower, ci_upper, se, delta, log_se, log_delta)) }}r1 <-ci_from_p(0.032, -22, type ="DIFF")r2 <-ci_from_p(0.032, -8, type ="DIFF")r3 <-ci_from_p(0.032, -12, type ="DIFF")r4 <-ci_from_p(0.032, 7, type ="DIFF")r5 <-ci_from_p(0.032, -52, type ="DIFF")r6 <-ci_from_p(0.032, 12, type ="DIFF")r7 <-ci_from_p(0.032, 52, type ="DIFF")A <-matrix(r1, nrow =1, ncol =4)A <-rbind(A, r2, r3, r4, r5, r6, r7)dimnames(A) <-list(c("e1", "e2", "e3", "e4", "e5", "e6", "e7"), c("CI_lower", "CI_upper", "SE", "Delta"))library(ggplot2)ggplot(data =as.data.frame(A), aes(y =rownames(A), x = Delta)) +geom_point() +geom_errorbar(aes(xmin = CI_lower, xmax = CI_upper), width =0.2) +ylab("Estudo") +xlab("Diferença de médias") +geom_vline(xintercept =0, linetype ="solid", colour ="red") +theme_minimal()
Ordene os valores de p do estudo e1 a e7.
Resposta (clique no Code abaixo):
Code
# O valor de p de todos os estudos é o mesmo, 0.032.# Perceba que o estudo e2, e4 e e6 não tocam a linha da nulidade# (apesar da escala da figura nos enganar).# Este exemplo nos ensina duas lições importantes:# 1) Estudos com o mesmo valor de p podem ter diferentes implicações práticas, ou seja,# apenas o valor de p não é suficiente para a tomada de decisão.# 2) A inspeção visual de intervalos de confiança pode nos enganar quanto ao valor de p# dos estudos. Se desejamos comparar valores de p, precisamos calculá-los.
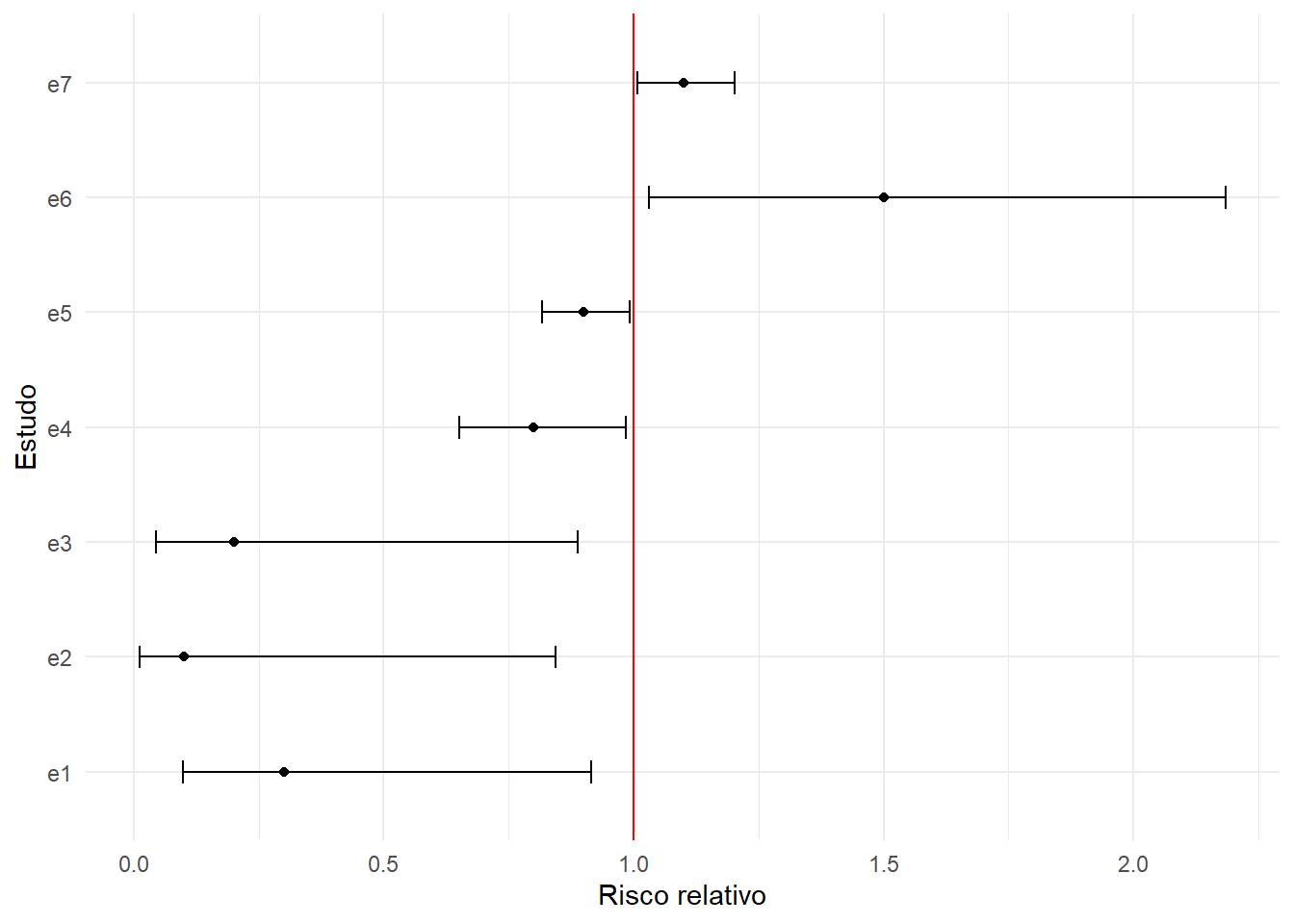
O mesmo exemplo acima se aplica para um desfecho dicotômico:
Code
a1 <-ci_from_p(0.034, 0.30, type ="RATIO")a2 <-ci_from_p(0.034, 0.10, type ="RATIO")a3 <-ci_from_p(0.034, 0.20, type ="RATIO")a4 <-ci_from_p(0.034, 0.80, type ="RATIO")a5 <-ci_from_p(0.034, 0.90, type ="RATIO")a6 <-ci_from_p(0.034, 1.50, type ="RATIO")a7 <-ci_from_p(0.034, 1.10, type ="RATIO")B <-matrix(a1, nrow =1, ncol =6)B <-rbind(B, a2, a3, a4, a5, a6, a7)dimnames(B) <-list(c("e1", "e2", "e3", "e4", "e5", "e6", "e7"), c("CI_lower", "CI_upper", "SE", "delta", "log_SE", "log_delta"))library(ggplot2)ggplot(data =as.data.frame(B), aes(y =rownames(B), x = delta)) +geom_point() +geom_errorbar(aes(xmin = CI_lower, xmax = CI_upper), width =0.2) +ylab("Estudo") +xlab("Risco relativo") +geom_vline(xintercept =1, linetype ="solid", colour ="red") +theme_minimal()
Resposta (clique no Code abaixo):
Code
# O valor de p de todos os estudos é 0.034.# Perceba que o estudo e4, e5 e e7 não tocam a linha da nulidade# (apesar da escala da figura nos enganar).
---title: "Estatística inferencial"author: RLPformat: html: code-fold: true code-tools: truecss: style.csseditor_options: chunk_output_type: inlineexecute: warning: false---**Como citar o conteúdo deste site**Pacheco RL, Martimbianco ALC, Riera, R. Medidas de tamanho de efeito. 2023. Disponível em: www.nepsbeats.com.Última atualização: 23/abril/2024.------------------------------------------------------------------------Continuaremos analisando um ensaio clínico randomizado que possui o seguinte PICO:- P: participantes com Covid-19 grave- I: "covidina"- C: placebo- O: mortalidade em 28 dias e tempo de internaçãoA hipótese principal do estudo é a de que a covidina reduziria a mortalidade e o tempo de internação dos pacientes com Covid-19 em 28 dias, podendo ser utilizada no tratamento de pacientes graves. No total, o ensaio clínico recrutou 200 participantes para o grupo covidina e 200 participantes para o grupo placebo.```{r}set.seed(150393)n <-400n_group <-200#df controlgroup <-rep("Placebo", n_group)died <-sample(c("Alive", "Dead"), n_group, replace =TRUE, prob = (c(0.50, 0.50)))days_hosp <-rnorm(n_group, mean =18, sd =4)days_hosp <-round(days_hosp)age <-rnorm(n_group, mean =60, sd =30)age <-ifelse(age <18, 18, age)age <-ifelse(age >90, 90, age)age <-round(age)df_control <-data.frame(group, age, days_hosp, died)# df intgroup <-rep("Intervention", n_group)died <-sample(c("Alive", "Dead"), n_group, replace =TRUE, prob = (c(0.75, 0.25)))days_hosp <-rnorm(n_group, mean =12, sd =3)days_hosp <-round(days_hosp)age <-rnorm(n_group, mean =60, sd =30)age <-ifelse(age <18, 18, age)age <-ifelse(age >90, 90, age)age <-round(age)df_int <-data.frame(group, age, days_hosp, died)df <-rbind(df_control, df_int)df <- df[sample(nrow(df)),]id <-1:ndf <-data.frame(id, df)```**Base 1**. Base de dados do ensaio clínico randomizado que avaliou a covidina para Covid-19 grave.```{r}knitr::kable(df[1:10, ], )```**Tabela 1**. Tabela de contingência do ensaio clínico randomizado que avaliou a covidina para Covid-19 grave.+----------+---------+---------+---------+| | Morto | Vivo | Total |+:========:+:=======:+:=======:+:=======:+| Covidina | 55 | 145 | 200 || | | | || | (27.5%) | (72.5%) | (100%) |+----------+---------+---------+---------+| Placebo | 114 | 86 | 200 || | | | || | (57%) | (43%) | (100%) |+----------+---------+---------+---------+Pela tabela de contingência, observamos que o risco relativo do estudo é 0,48 e o odds ratio é 0,29.### Generalizando os resultados do estudo para a populaçãoO risco relativo e o *odds ratio* calculados são as estimativas pontuais do estudo que descrevem o que aconteceu com os 400 prticipantes do ensaio clínico em questão.No entanto, estamos interessados em utilizar os dados desta amostra para extrapolar a conclusão para a “população”. Em um ensaio clínico randomizado, a população pode ser assumida como os pacientes que serão tratados na prática e que possuem características semelhantes aos participantes do estudo.Uma das formas de fazer esses processos inferenciais é por meio de testes de hipótese. Podemos realizar um teste Chi².```{r}chisq.test(df$died, df$group, correct =FALSE)```O valor de p identificado é muito pequeno (Pr = 2.341e-09 = 0.000000002341) e frequentemente seria considerado como estatisticamente significante pelo autor do estudo. A interpretação é a de que podemos afastar a hipótese nula com segurança, ou de que estamos confiantes de que haja algum efeito na redução de mortalidade com o uso da intervenção na população.Apesar de frequente, os testes de hipótese levam para outra pergunta intuitiva: qual é a magnitude de efeito compatível com o uso da intervenção?O intervalo de confiança é uma medida inferencial que pode ser interpretada como um intervalo de valores compatíveis com o efeito da intervenção na população. A análise a seguir apresenta o intervalo de confiança do risco relativo e o intervalo de confiança do *odds ratio*.```{r}es_dic <-function(i_events, i_n, c_events, c_n) { rr <- (i_events/i_n) / (c_events/c_n) rr <-round(rr, digits =2) se_rr <-sqrt( (((i_n-i_events)/i_events)/i_n) + (((c_n-c_events)/c_events)/c_n) ) upper_limit_rr <-exp(log(rr) +1.96*se_rr) upper_limit_rr <-round(upper_limit_rr, digits =2) lower_limit_rr <-exp(log(rr) -1.96*se_rr) lower_limit_rr <-round(lower_limit_rr, digits =2) or <- (i_events/(i_n - i_events)) / (c_events/(c_n - c_events)) or <-round(or, digits =2) se_or <-sqrt(1/i_events +1/(i_n - i_events) +1/c_events +1/(c_n - c_events)) upper_limit_or <-exp(log(or) +1.96*se_or) upper_limit_or <-round(upper_limit_or, digits =2) lower_limit_or <-exp(log(or) -1.96*se_or) lower_limit_or <-round(lower_limit_or, digits =2) ri <- i_events/i_n rc <- c_events/c_n rd <- ri - rc rd <-round(rd, digits =2) upper_limit_rd <- rd +1.96*sqrt( (ri*(1-ri)/i_n) + (rc*(1-rc)/c_n) ) upper_limit_rd <-round(upper_limit_rd, digits =2) lower_limit_rd <- rd -1.96*sqrt( (ri*(1-ri)/i_n) + (rc*(1-rc)/c_n) ) lower_limit_rd <-round(lower_limit_rd, digits =2) e_int_event <- (i_events+c_events)*(i_n)/(i_n+c_n) e_cont_event <- (i_events+c_events)*(c_n)/(i_n+c_n) e_int_nonevent <- i_n - e_int_event e_cont_nonevent <- c_n - e_cont_event chi_sqr <- ((i_events - e_int_event)^2/e_int_event) + ((c_events - e_cont_event)^2/e_cont_event) + ((i_n - i_events - e_int_nonevent)^2/e_int_nonevent) + ((c_n - c_events - e_cont_nonevent)^2/e_cont_nonevent) chi_sqr <-round(chi_sqr, digits =3) p_value <-1-pchisq(chi_sqr, 1) p_value <-round(p_value, digits =12)print(paste0("The risk in the intervention group is = ", i_events/i_n))print(paste0("The risk in the control group is = ", c_events/c_n))print(paste0("The relative risk is = ", rr, " (95% Confidence Interval = ", lower_limit_rr, " to ", upper_limit_rr,")" ))print(paste0("The risk difference is = ", rd, " (95% Confidence Interval = ", lower_limit_rd, " to ", upper_limit_rd,")" ))print(paste0("The odds ratio is = ", or, " (95% Confidence Interval = ", lower_limit_or, " to ", upper_limit_or,")" ))print(paste0("The chi-squared value is = ", chi_sqr))print(paste0("The p-value is = ", p_value))}es_dic(55, 200, 114, 200)```Os resultados deste estudo poderiam ser descritos das seguintes formas:(1) Risco relativo = 0.48; IC95% = 0.37 a 0.62; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de risco de 38% a 63% com o uso da intervenção.(2) *Odds ratio* = 0.29; IC95% = 0.19 a 0.44; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de *odds* de 56% a 81% com o uso da intervenção.Ambos os resultados são válidos, e a interpretação deve levar em conta se o *odds ratio* ou o risco relativo foram calculados.A maior limitação dos testes de hipótese, como o Chi², é que eles não podem ser ajustados por variáveis consideradas importantes pelos pesquisadores do estudo. Com base na análise anterior, estimou-se o seguinte resultado:- *Odds ratio* = 0.29; IC95% = 0.19 a 0.44; p = 0000. Os resultados indicam que o intervalo é compatível com uma redução de *odds* de 56% a 81% com o uso da intervenção.Uma outra forma de calcular o resultado seria pela utilização de regressão logística ou algum outro modelo generalizado.```{r}#| output: falselibrary(tidyverse)df <- df %>%mutate(died_num =ifelse(died =="Dead", 1, 0))df <- df %>%mutate(group_num =ifelse(group =="Intervention", 1, 0))reg_logistica <-glm(died_num ~ group_num, data = df, family ="binomial"(link ="logit"))summary(reg_logistica)or <-exp(coef(reg_logistica))ci <-exp(confint(reg_logistica))orci# Output is omitted```O resultado da análise de regressão não ajustada é o mesmo *odds ratio* calculado (considerando mínimas diferenças de arredondamento e fórmulas).Também pode-se chegar ao mesmo risco relativo calculado anteriormente por meio de um modelo linear generalizado (risco relativo = 0.48; IC95% = 0.37 a 0.62; p = 0.0000).```{r}#| output: falselibrary(risks)fit_rr <-riskratio(formula = died_num ~ group_num, data = df, approach ="glm")summary(fit_rr)rr <-exp(coef(fit_rr))ci_rr <-exp(confint(fit_rr))rrci_rr# Output is omitted```### Análises ajustadas vs. não ajustadasOs modelos de regressão apresentados podem ser ajustados por variáveis consideradas importantes pelos autores do estudo.O código a seguir demonstra a análise de regressão logística ajustada pela idade.```{r}#| output: falselibrary(tidyverse)reg_logistica <-glm(died_num ~ group_num + age, data = df, family ="binomial"(link ="logit"))summary(reg_logistica)or <-exp(coef(reg_logistica))ci <-exp(confint(reg_logistica))orci# Output is omitted```Neste caso, o resultado da análise ajustada foi similar ao da análise não-ajustada.O estudo poderia relatar a seguinte informação:- *Odds ratio* ajustado pela idade = 0.286; IC95% = 0.187 a 0.433; p = 0.0000).Este ajuste também poderia ser realizado no modelo linear utilizado para o cálculo do risco relativo. Ainda, mais de uma variável pode ser considerada para a realização do ajuste, como por exemplo o sexo.A escolha das variáveis a serem utilizadas é um passo muito importante no planejamento da análise estatística, e deve levar em conta o conhecimento prévio sobre a doença e estudos anteriores na área.Análises ajustadas podem ser motivo de debate ao interpretar o resultado de estudos clínicos, pois dependendo das variáveis utilizadas no modelo os resultados podem ser diferentes. Nem sempre os especialistas concordam sobre os ajustes realizados e em muitos casos a escolha das variáveis de um modelo é baseada em critérios inadequados.No caso em análise, a estimativa do *odds ratio* e seu intervalo de confiança são ligeiramente diferentes da análise não-ajustada, mas a conclusão geral deve ser a mesma nesse exemplo: estamos confiantes que é esperado um efeito importante na redução de mortalidade para a população que receberá a intervenção na prática.#### Cuidado ao inspecionar intervalos de confiançaA figura abaixo apresenta o intervalo de confiança de sete estudos cujo desfecho principal é uma diferença de médias entre duas intervenções.```{r}ci_from_p <-function(p, delta, type ="DIFF") {if (type =="DIFF") { z <--0.862+sqrt(0.743-2.404*log(p)) se <-abs(delta / z) ci_limit <- se*1.96 ci_lower <- delta - ci_limit ci_upper <- delta + ci_limitreturn(c(ci_lower, ci_upper, se, delta)) } if(type =="RATIO") { z <--0.862+sqrt(0.743-2.404*log(p)) est <-log(delta) se <-abs(est / z) ci_limit <- se*1.96 ci_lower <-exp(est - ci_limit) ci_upper <-exp(est + ci_limit) log_se <-log(se) log_delta <-log(delta)return(c(ci_lower, ci_upper, se, delta, log_se, log_delta)) }}r1 <-ci_from_p(0.032, -22, type ="DIFF")r2 <-ci_from_p(0.032, -8, type ="DIFF")r3 <-ci_from_p(0.032, -12, type ="DIFF")r4 <-ci_from_p(0.032, 7, type ="DIFF")r5 <-ci_from_p(0.032, -52, type ="DIFF")r6 <-ci_from_p(0.032, 12, type ="DIFF")r7 <-ci_from_p(0.032, 52, type ="DIFF")A <-matrix(r1, nrow =1, ncol =4)A <-rbind(A, r2, r3, r4, r5, r6, r7)dimnames(A) <-list(c("e1", "e2", "e3", "e4", "e5", "e6", "e7"), c("CI_lower", "CI_upper", "SE", "Delta"))library(ggplot2)ggplot(data =as.data.frame(A), aes(y =rownames(A), x = Delta)) +geom_point() +geom_errorbar(aes(xmin = CI_lower, xmax = CI_upper), width =0.2) +ylab("Estudo") +xlab("Diferença de médias") +geom_vline(xintercept =0, linetype ="solid", colour ="red") +theme_minimal()```Ordene os valores de p do estudo e1 a e7.**Resposta** (clique no Code abaixo):```{r}# O valor de p de todos os estudos é o mesmo, 0.032.# Perceba que o estudo e2, e4 e e6 não tocam a linha da nulidade# (apesar da escala da figura nos enganar).# Este exemplo nos ensina duas lições importantes:# 1) Estudos com o mesmo valor de p podem ter diferentes implicações práticas, ou seja,# apenas o valor de p não é suficiente para a tomada de decisão.# 2) A inspeção visual de intervalos de confiança pode nos enganar quanto ao valor de p# dos estudos. Se desejamos comparar valores de p, precisamos calculá-los. ```O mesmo exemplo acima se aplica para um desfecho dicotômico:```{r}a1 <-ci_from_p(0.034, 0.30, type ="RATIO")a2 <-ci_from_p(0.034, 0.10, type ="RATIO")a3 <-ci_from_p(0.034, 0.20, type ="RATIO")a4 <-ci_from_p(0.034, 0.80, type ="RATIO")a5 <-ci_from_p(0.034, 0.90, type ="RATIO")a6 <-ci_from_p(0.034, 1.50, type ="RATIO")a7 <-ci_from_p(0.034, 1.10, type ="RATIO")B <-matrix(a1, nrow =1, ncol =6)B <-rbind(B, a2, a3, a4, a5, a6, a7)dimnames(B) <-list(c("e1", "e2", "e3", "e4", "e5", "e6", "e7"), c("CI_lower", "CI_upper", "SE", "delta", "log_SE", "log_delta"))library(ggplot2)ggplot(data =as.data.frame(B), aes(y =rownames(B), x = delta)) +geom_point() +geom_errorbar(aes(xmin = CI_lower, xmax = CI_upper), width =0.2) +ylab("Estudo") +xlab("Risco relativo") +geom_vline(xintercept =1, linetype ="solid", colour ="red") +theme_minimal()```**Resposta** (clique no Code abaixo):``` {r} # O valor de p de todos os estudos é 0.034.# Perceba que o estudo e4, e5 e e7 não tocam a linha da nulidade# (apesar da escala da figura nos enganar).```