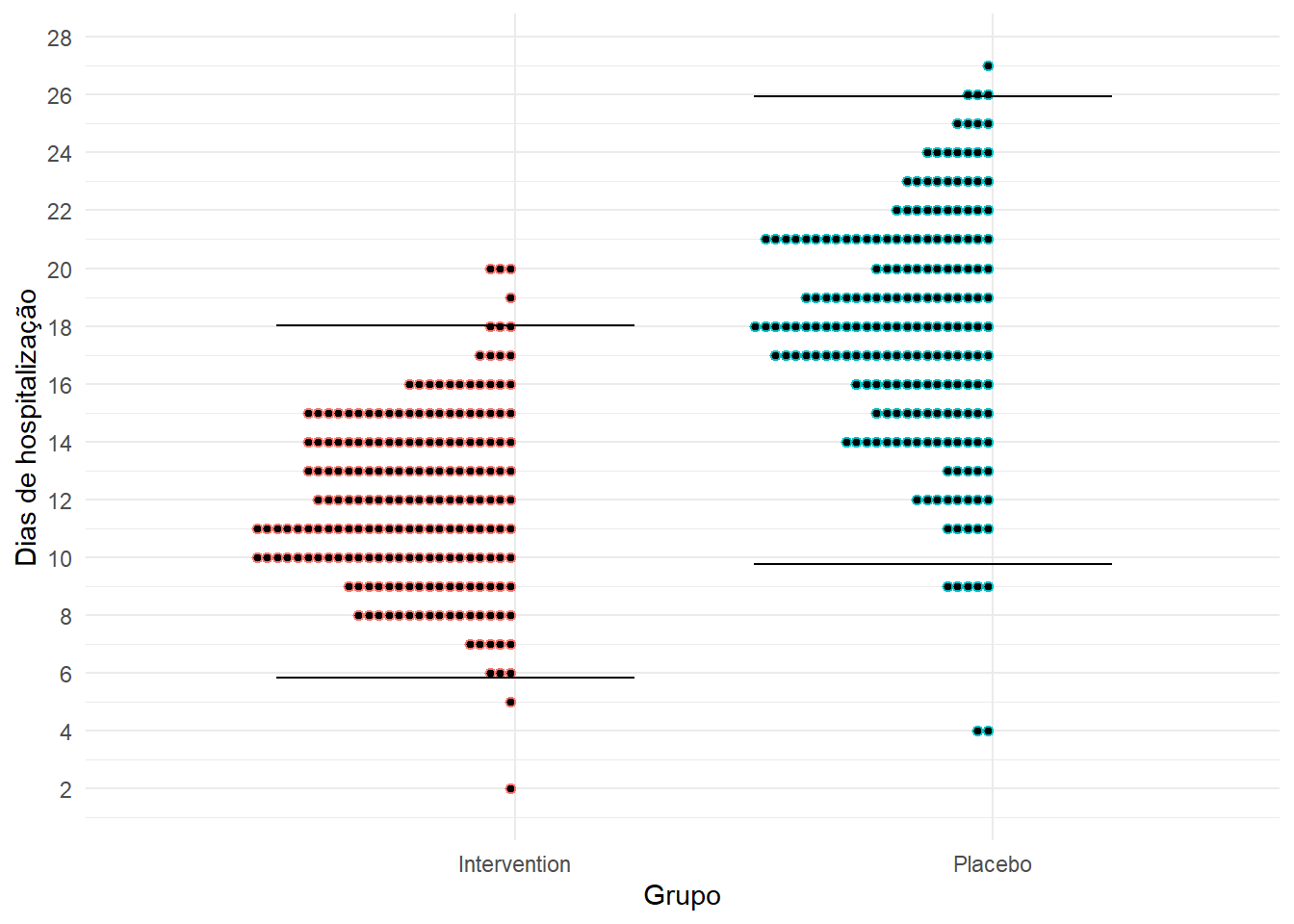Você está analisando um ensaio clínico randomizado que possui o seguinte PICO:
P: participantes com Covid-19 grave
I: “covidina”
C: placebo
O: mortalidade em 28 dias e tempo de internação
A hipótese principal do estudo é a de que a covidina reduziria a mortalidade e o tempo de internação dos pacientes com Covid-19 em 28 dias, podendo ser utilizada no tratamento de pacientes graves.
Uma base de com dados com as principais variáveis deste estudo se pareceria com:
Base 1. Base de dados do ensaio clínico randomizado que avaliou a covidina para pacientes com Covid-19 grave.
Code
knitr::kable(df[1:10, ], )
id
group
age
days_hosp
died
35
1
Placebo
57
21
Dead
394
2
Intervention
24
9
Alive
178
3
Placebo
90
15
Dead
78
4
Placebo
18
17
Alive
378
5
Intervention
85
14
Alive
57
6
Placebo
77
16
Alive
82
7
Placebo
61
14
Dead
274
8
Intervention
72
7
Alive
316
9
Intervention
72
13
Alive
95
10
Placebo
71
22
Alive
As colunas significam:
Id : identificação do participante (atribuído no momento da randomizado)
Group: identificação de qual intervenção o paciente recebeu
Age: idade do paciente no momento da randomização (linha de base)
Died: identificação se o paciente estava morto ou vivo 28 dias após a randomização
Tempo_hosp: o tempo total de hospitalização em dias.
No total, o ensaio clínico recrutou 200 participantes para o grupo covidina e 200 para o grupo placebo.
Code
table(df$group)
Intervention Placebo
200 200
O primeiro passo de qualquer análise é sempre descrever os participantes. Não se pode simplesmente apresentar o que aconteceu com cada participante individualmente. A base de dados deste estudo possui 400 linhas, e, descrever cada “linha” individualmente não só seria pouco eficiente mas também de difícil compreensão. Quase tudo o que precisamos para descrever os dados em um ensaio clínico randomizado é intuitivo. Por exemplo, podemos descrever a porcentagem de pacientes que morreram em cada grupo para comparar a mortalidade dos dois grupos.
Code
table(df$group, df$died)
Alive Dead
Intervention 145 55
Placebo 86 114
Podemos notar que dos 200 participantes que receberam placebo, 57% (114/200) estavam mortos no dia 28. Em comparação, apenas 27,5% (55/200) dos que receberam covidina tinham morrido.
Não precisamos de muita “estatística” para perceber que neste estudo a mortalidade no grupo intervenção foi aproximadamente a metade do grupo placebo. Discutiremos posteriormente como extrapolar os resultados deste estudo para os pacientes que serão tratados (“população”).
Uma variável como “morte em 28 dias” é chamada de categórica, pois divide os pacientes em categorias. Mais especificamente, quando uma variável categórica possui apenas duas categorias, como “vivo” ou “morto”, ela é chamada de dicotômica.
Também é intuitivo perceber que não é a melhor abordagem apresentar a porcentagem de participantes com números diferentes de dias de internação.
Por exemplo, na tabela acima vemos que nenhum participante do grupo placebo e um do grupo intervenção ficaram 2 dias hospitalizados, nenhum participante do grupo intervenção e dois do grupo placebo ficaram 4 dias hospitalizados, e assim por diante…
Para uma variável contínua, como o tempo para hospitalização, o ideal é descrever os dados utilizando outra abordagem que não porcentagens. Utilizaremos as medidas de tendência central e de dispersão.
Code
summary_by_group <-aggregate(df$days_hosp, list(df$group), FUN = summary)sd_by_group <-aggregate(df$days_hosp, list(df$group), FUN = sd)
O código acima calcula as principais medidas para descrever uma variável contínua como o tempo de hospitalização.
A tabela 1 apresenta a comparação das principais medidas de estatística descritiva (arredondadas) dos dois grupos.
Tabela 1. Comparação do tempo de hospitalização (em dias) dos dois grupos
Medida
Placebo
Covidina
Média
18
12
Desvio-padrão
4
3
Mediana (50%)
18
12
Quartil 1 (25%)
15
10
Quartil 3 (75%)
21
14
Mínimo
4
2
Máximo
27
20
A média possui uma interpretação intuitiva, que aprendemos desde o momento em que calculamos as médias de notas em provas na escola!
O valor mínimo e máximo são autoexplicativos. O participante com menor tempo de hospitalização no grupo placebo ficou 4 dias hospitalizados e o com maior tempo, 27 dias.
A mediana, também conhecida como Quartil 2, representa o valor máximo que “a primeira metade possui”, ordenados do menor para o maior valor. O quartil 1 e 3, por sua vez, representam o valor máximo que 25% e 75% da amostra possuem.
Por exemplo, podemos dizer que os primeiros 100 participantes do grupo covidina (50% da amostra) possuíam até 12 dias de hospitalização. Como sabemos que o mínimo foi 2 dias, podemos dizer que os primeiros 100 participantes possuíam de 2 a 12 dias de hospitalização.
Também sabemos que os primeiros 50 participantes do grupo covidina (25% da amostra) possuíam de 3 a 10 dias de hospitalização.
Os primeiros 150 participantes do grupo covidina (75% da amostra) possuíam tempo de hospitalização de 2 a 10 dias. Ou ainda, que os 50 últimos participantes possuem valor entre 14 e 20 dias.
Nota-se que esta interpretação leva em conta o ordenamento sequencial dos participantes do menor ao maior valor. Uma outra forma de afirmar a mesma coisa é: os 50 participantes com menor tempo de hospitalização, possuíam valor entre 2 e 10 dias de hospitalização e os 50 participantes com maior tempo de hospitalização, possuíam valor entre 14 e 20 dias.
E assim por diante…
Também podemos saber o valor dos 50% participantes “do meio”, ou seja, o “recheio” da amostra. Os 100 participantes “do meio” possuíam valor entre o quartil 1 e 3, ou seja, entre 10 e 14 dias. A diferença entre o quartil 3 e 1 é chamado de intervalo interquartil
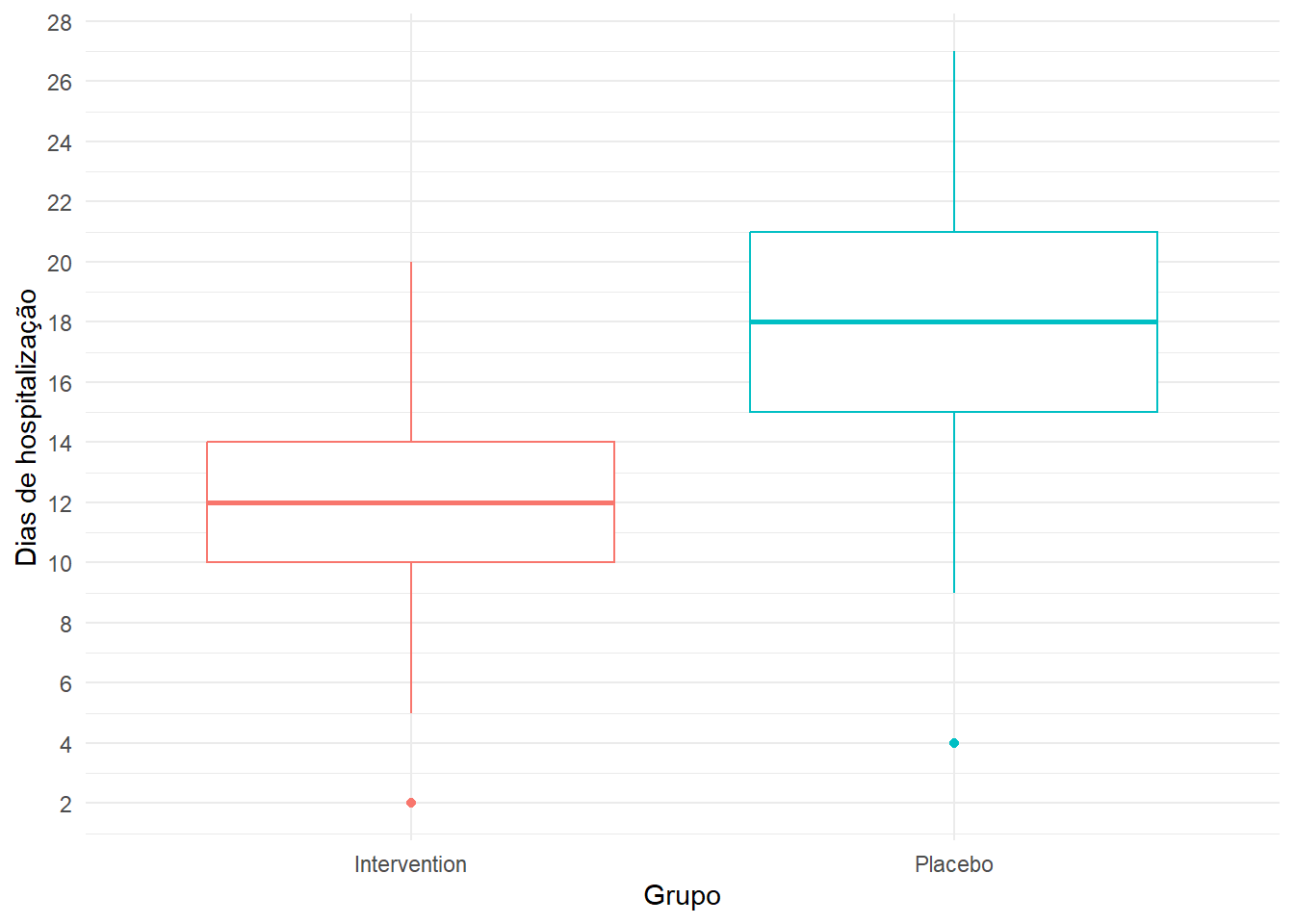
O box-plot
Um box-plot nada mais é do que uma forma gráfica de apresentar os dados da tabela 1. Mais especificamente, ele apresenta a mediana e os quartis 1 e 3.
A definição dos limites da linha vertical (também conhecida como whiskers ou bigodes) é o maior/menor valor que está dentro do intervalo = 1,5x(Q3-Q1). Ou seja, a 1,5xIQR. Valores eventuais fora deste intervalo são marcados como outliers (pontos). Vale ressaltar que existem definições diferentes dos whiskers na literatura, mas a mais comum é esta.
O boxplot abaixo mostra que os valores dos Q1 e Q3 da tabela 1 coincidem com os lados horizontais do retângulo e a mediana (Q2) com a linha central.
Code
library(ggplot2)ggplot(df, aes(x = group, y = days_hosp, colour = group)) +geom_boxplot() +ylab("Dias de hospitalização") +xlab("Grupo") +scale_y_continuous(breaks =seq(0, 30, by =2)) +theme_minimal() +theme(legend.position="none")
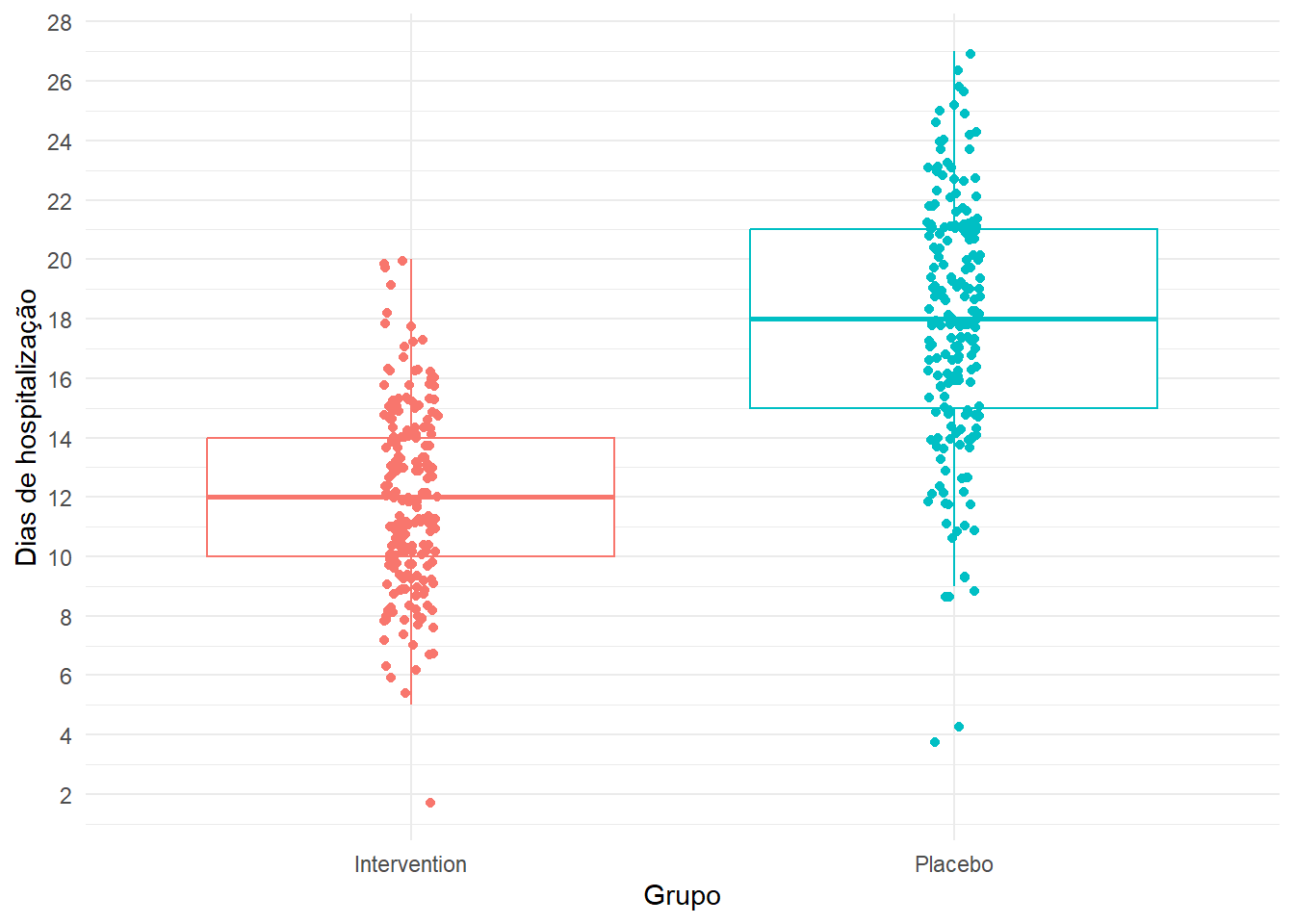
O box-plot também pode ser combinado com um dot-plot, que representa cada participamente individualmente.
Code
library(ggplot2)ggplot(df, aes(x = group, y = days_hosp, colour = group)) +geom_boxplot(outlier.shape=NA) +geom_jitter(width =0.05) +ylab("Dias de hospitalização") +xlab("Grupo") +scale_y_continuous(breaks =seq(0, 30, by =2)) +theme_minimal() +theme(legend.position="none")
E o desvio-padrão?
O desvio-padrão é uma medida de dispersão que nos ajuda a entender qual o valor esperado para “a maior parte” dos participantes.
Tecnicamente, a regra geral de interpretação do desvio-padrão é que 66% da amostra estará dentro dos limites de 1 desvio-padrão acima e abaixo da média. E que 95% da amostra, ou seja, “a maior parte”, estará entre 2 desvios-padrão acima e abaixo da média.
Na figura 1, cada ponto indica o valor de tempo de hospitalização de um participante do estudo.
Figura 1. Distribuição de valores de tempo de hospitalização nos dois grupos
As linhas pretas são os valores de 2 desvio-padrão acima e abaixo da média do grupo placebo e intervenção.
Deste modo, podemos concluir:
É esperado que “a maior parte” (95%) dos 200 participantes do grupo placebo tenha tempo de hospitalização entre 12 e 28 dias.
É esperado que “a maior parte” dos 200 participantes do grupo intervenção tenha tempo de hospitalização entre 6 e 18 dias.
Esta regra de interpretação do desvio-padrão é válida principalmente quando a distribuição da variável é “normal”. Perceba pela Figura 1 o formato gaussiano do tempo de hospitalização.
Quem analisará os dados relatará as medidas descritivas mais adequadas. Ou, como mais frequentemente encontrado em publicações recentes, ele apresentará todas as medidas úteis para o leitor conseguir interpretá-las.
O que acontece se a distribuição não for normal?
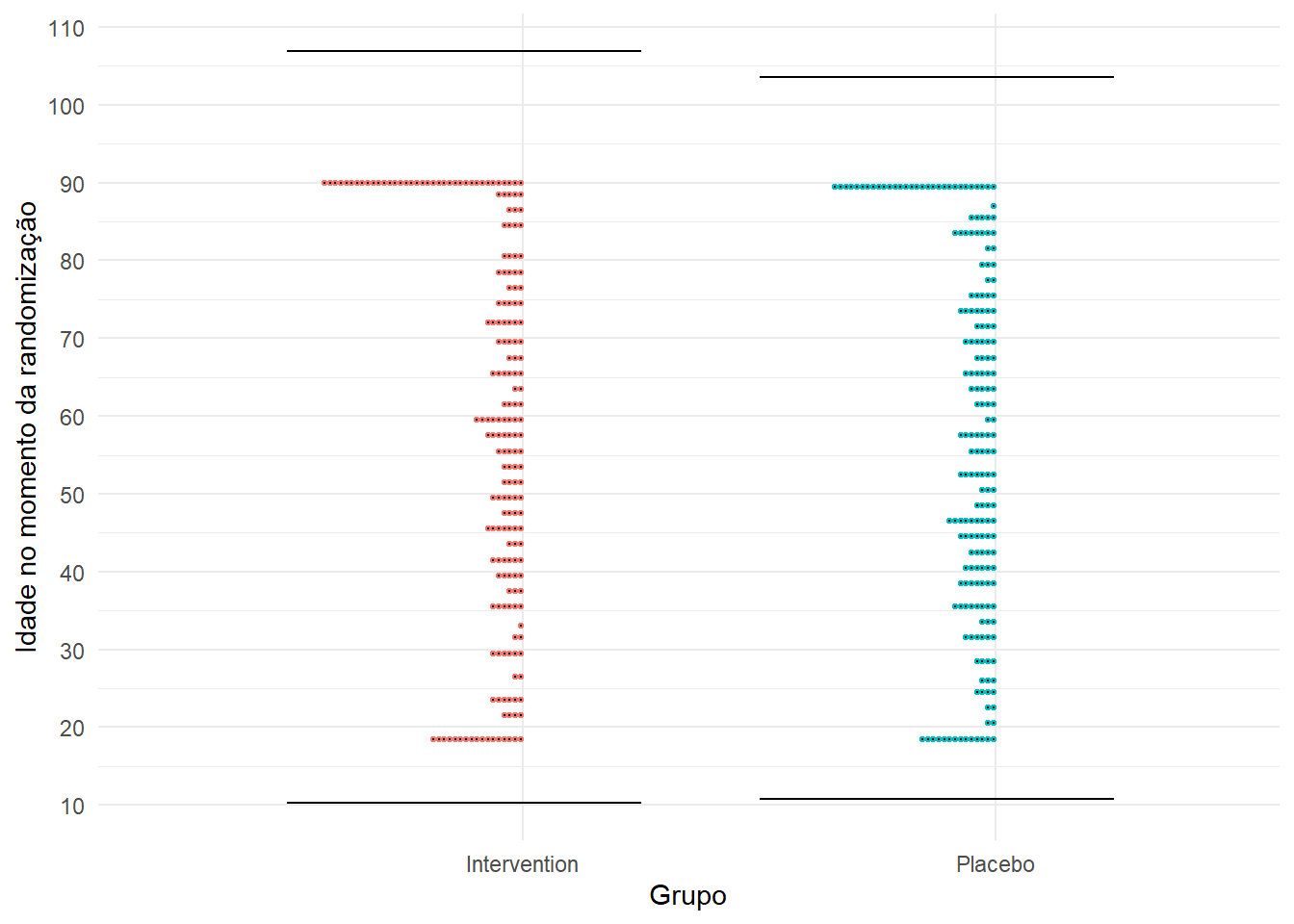
Vamos repetir a Figura 1, mas olhando a distribuição de idades por grupo.
Figura 2. Distribuição de valores de idade nos dois grupos
A Figura 2 mostra a distribuição de idades nos dois grupos. Perceba que a distribuição de idades não é normal. A distribuição de idades é assimétrica, pois o estudo não incluiu participantes com menos de 18 anos e com mais de 90 anos.
Apesar de não ser completamente incorreto pensar que “a maior parte dos dados está entre dois desvios-padrão da média de idade”, fica claro que a regra geral do desvio-padrão não é a forma mais adequada para descrever a distribuição de idade. Aqui, um bom pesquisador daria ênfase a medidas como os quartis e a mediana.
---title: "Estatística descritiva"author: RLPformat: html: code-fold: true code-tools: truecss: style.csseditor_options: chunk_output_type: inlineexecute: warning: false---**Como citar o conteúdo deste site**Pacheco RL, Martimbianco ALC, Riera, R. Estatística descritiva. 2023. Disponível em: www.nepsbeats.com.Última atualização: 26/mar/2024.------------------------------------------------------------------------Você está analisando um ensaio clínico randomizado que possui o seguinte PICO:- P: participantes com Covid-19 grave- I: "covidina"- C: placebo- O: mortalidade em 28 dias e tempo de internaçãoA hipótese principal do estudo é a de que a covidina reduziria a mortalidade e o tempo de internação dos pacientes com Covid-19 em 28 dias, podendo ser utilizada no tratamento de pacientes graves.```{r}set.seed(150393)n <-400n_group <-200#df controlgroup <-rep("Placebo", n_group)died <-sample(c("Alive", "Dead"), n_group, replace =TRUE, prob = (c(0.50, 0.50)))days_hosp <-rnorm(n_group, mean =18, sd =4)days_hosp <-round(days_hosp)age <-rnorm(n_group, mean =60, sd =30)age <-ifelse(age <18, 18, age)age <-ifelse(age >90, 90, age)age <-round(age)df_control <-data.frame(group, age, days_hosp, died)# df intgroup <-rep("Intervention", n_group)died <-sample(c("Alive", "Dead"), n_group, replace =TRUE, prob = (c(0.75, 0.25)))days_hosp <-rnorm(n_group, mean =12, sd =3)days_hosp <-round(days_hosp)age <-rnorm(n_group, mean =60, sd =30)age <-ifelse(age <18, 18, age)age <-ifelse(age >90, 90, age)age <-round(age)df_int <-data.frame(group, age, days_hosp, died)df <-rbind(df_control, df_int)df <- df[sample(nrow(df)),]id <-1:ndf <-data.frame(id, df)```Uma base de com dados com as principais variáveis deste estudo se pareceria com:**Base 1**. Base de dados do ensaio clínico randomizado que avaliou a covidina para pacientes com Covid-19 grave.```{r}knitr::kable(df[1:10, ], )```As colunas significam:``` Id : identificação do participante (atribuído no momento da randomizado)Group: identificação de qual intervenção o paciente recebeuAge: idade do paciente no momento da randomização (linha de base)Died: identificação se o paciente estava morto ou vivo 28 dias após a randomizaçãoTempo_hosp: o tempo total de hospitalização em dias.```No total, o ensaio clínico recrutou 200 participantes para o grupo covidina e 200 para o grupo placebo.```{r}table(df$group)```O primeiro passo de qualquer análise é sempre descrever os participantes. Não se pode simplesmente apresentar o que aconteceu com cada participante individualmente. A base de dados deste estudo possui 400 linhas, e, descrever cada "linha" individualmente não só seria pouco eficiente mas também de difícil compreensão. Quase tudo o que precisamos para descrever os dados em um ensaio clínico randomizado é intuitivo. Por exemplo, podemos descrever a porcentagem de pacientes que morreram em cada grupo para comparar a mortalidade dos dois grupos.```{r}table(df$group, df$died)```Podemos notar que dos 200 participantes que receberam placebo, 57% (114/200) estavam mortos no dia 28. Em comparação, apenas 27,5% (55/200) dos que receberam covidina tinham morrido.Não precisamos de muita "estatística" para perceber que **neste** estudo a mortalidade no grupo intervenção foi aproximadamente a metade do grupo placebo. Discutiremos posteriormente como extrapolar os resultados deste estudo para os pacientes que serão tratados ("população").Uma variável como "morte em 28 dias" é chamada de categórica, pois divide os pacientes em categorias. Mais especificamente, quando uma variável categórica possui apenas duas categorias, como "vivo" ou "morto", ela é chamada de dicotômica.Também é intuitivo perceber que não é a melhor abordagem apresentar a porcentagem de participantes com números diferentes de dias de internação.```{r}table(df$days_hosp, df$group)```Por exemplo, na tabela acima vemos que nenhum participante do grupo placebo e um do grupo intervenção ficaram 2 dias hospitalizados, nenhum participante do grupo intervenção e dois do grupo placebo ficaram 4 dias hospitalizados, e assim por diante...Para uma variável contínua, como o tempo para hospitalização, o ideal é descrever os dados utilizando outra abordagem que não porcentagens. Utilizaremos as medidas de tendência central e de dispersão.```{r}summary_by_group <-aggregate(df$days_hosp, list(df$group), FUN = summary)sd_by_group <-aggregate(df$days_hosp, list(df$group), FUN = sd)```O código acima calcula as principais medidas para descrever uma variável contínua como o tempo de hospitalização.A **tabela 1** apresenta a comparação das principais medidas de estatística descritiva (arredondadas) dos dois grupos.**Tabela 1**. Comparação do tempo de hospitalização (em dias) dos dois grupos| Medida | Placebo | Covidina ||:---------------:|:-------:|:--------:|| Média | 18 | 12 || Desvio-padrão | 4 | 3 || Mediana (50%) | 18 | 12 || Quartil 1 (25%) | 15 | 10 || Quartil 3 (75%) | 21 | 14 || Mínimo | 4 | 2 || Máximo | 27 | 20 |A média possui uma interpretação intuitiva, que aprendemos desde o momento em que calculamos as médias de notas em provas na escola!O valor mínimo e máximo são autoexplicativos. O participante com menor tempo de hospitalização no grupo placebo ficou 4 dias hospitalizados e o com maior tempo, 27 dias.A mediana, também conhecida como Quartil 2, representa o valor máximo que "a primeira metade possui", ordenados do menor para o maior valor. O quartil 1 e 3, por sua vez, representam o valor máximo que 25% e 75% da amostra possuem.Por exemplo, podemos dizer que os primeiros 100 participantes do grupo covidina (50% da amostra) possuíam até 12 dias de hospitalização. Como sabemos que o mínimo foi 2 dias, podemos dizer que os primeiros 100 participantes possuíam de 2 a 12 dias de hospitalização.Também sabemos que os primeiros 50 participantes do grupo covidina (25% da amostra) possuíam de 3 a 10 dias de hospitalização.Os primeiros 150 participantes do grupo covidina (75% da amostra) possuíam tempo de hospitalização de 2 a 10 dias. Ou ainda, que os 50 últimos participantes possuem valor entre 14 e 20 dias.Nota-se que esta interpretação leva em conta o ordenamento sequencial dos participantes do menor ao maior valor. Uma outra forma de afirmar a mesma coisa é: os 50 participantes com menor tempo de hospitalização, possuíam valor entre 2 e 10 dias de hospitalização e os 50 participantes com maior tempo de hospitalização, possuíam valor entre 14 e 20 dias.E assim por diante...Também podemos saber o valor dos 50% participantes "do meio", ou seja, o "recheio" da amostra. Os 100 participantes "do meio" possuíam valor entre o quartil 1 e 3, ou seja, entre 10 e 14 dias. A diferença entre o quartil 3 e 1 é chamado de *intervalo interquartil*#### O *box-plot*Um box-plot nada mais é do que uma forma gráfica de apresentar os dados da tabela 1. Mais especificamente, ele apresenta a mediana e os quartis 1 e 3.A definição dos limites da linha vertical (também conhecida como *whiskers* ou bigodes) é o maior/menor valor que está dentro do intervalo = 1,5x*(Q3-Q1)*. Ou seja, a 1,5x*IQR*. Valores eventuais fora deste intervalo são marcados como outliers (pontos). Vale ressaltar que existem definições diferentes dos *whiskers* na literatura, mas a mais comum é esta.O boxplot abaixo mostra que os valores dos Q1 e Q3 da tabela 1 coincidem com os lados horizontais do retângulo e a mediana (Q2) com a linha central.```{r}library(ggplot2)ggplot(df, aes(x = group, y = days_hosp, colour = group)) +geom_boxplot() +ylab("Dias de hospitalização") +xlab("Grupo") +scale_y_continuous(breaks =seq(0, 30, by =2)) +theme_minimal() +theme(legend.position="none") ```O box-plot também pode ser combinado com um dot-plot, que representa cada participamente individualmente.```{r}library(ggplot2)ggplot(df, aes(x = group, y = days_hosp, colour = group)) +geom_boxplot(outlier.shape=NA) +geom_jitter(width =0.05) +ylab("Dias de hospitalização") +xlab("Grupo") +scale_y_continuous(breaks =seq(0, 30, by =2)) +theme_minimal() +theme(legend.position="none") ```#### E o **desvio-padrão**?O desvio-padrão é uma medida de dispersão que nos ajuda a entender qual o valor esperado para "a maior parte" dos participantes.Tecnicamente, a regra geral de interpretação do desvio-padrão é que 66% da amostra estará dentro dos limites de 1 desvio-padrão acima e abaixo da média. E que 95% da amostra, ou seja, "a maior parte ", estará entre 2 desvios-padrão acima e abaixo da média.Na **figura 1**, cada ponto indica o valor de tempo de hospitalização de um participante do estudo.```{r}library(ggplot2)summary_by_group <-aggregate(df$days_hosp, list(df$group), FUN = summary)sd_by_group <-aggregate(df$days_hosp, list(df$group), FUN = sd)mean_sd <-data.frame(summary_by_group$x[, "Mean"], sd_by_group)mean_int <-mean(df$days_hosp[df$group =="Intervention"])sd_int <-sd(df$days_hosp[df$group =="Intervention"])int_upper <- mean_int + (2*sd_int)int_bottom <- mean_int - (2*sd_int)mean_control <-mean(df$days_hosp[df$group =="Placebo"])sd_control <-sd(df$days_hosp[df$group =="Placebo"])control_upper <- mean_control + (2*sd_control)control_bottom <- mean_control - (2*sd_control)ggplot(df, aes(x = group, y = days_hosp, colour = group)) +geom_dotplot(binaxis="y", stackdir="down", dotsize =0.35, binwidth =1) +ylab("Dias de hospitalização") +xlab("Grupo") +scale_y_continuous(breaks =seq(0, 30, by =2)) +geom_segment(aes(y = int_upper, yend = int_upper, x =0.5, xend =1.25), inherit.aes =FALSE) +geom_segment(aes(y = int_bottom, yend = int_bottom, x =0.5, xend =1.25), inherit.aes =FALSE) +geom_segment(aes(y = control_upper, yend = control_upper, x =1.5, xend =2.25), inherit.aes =FALSE) +geom_segment(aes(y = control_bottom, yend = control_bottom, x =1.5, xend =2.25), inherit.aes =FALSE) +theme_minimal() +theme(legend.position="none") ```**Figura 1**. Distribuição de valores de tempo de hospitalização nos dois gruposAs linhas pretas são os valores de 2 desvio-padrão acima e abaixo da média do grupo placebo e intervenção.Deste modo, podemos concluir:- É esperado que "a maior parte" (95%) dos 200 participantes do grupo placebo tenha tempo de hospitalização entre 12 e 28 dias.- É esperado que "a maior parte" dos 200 participantes do grupo intervenção tenha tempo de hospitalização entre 6 e 18 dias.Esta regra de interpretação do desvio-padrão é válida principalmente quando a distribuição da variável é "normal". Perceba pela **Figura 1** o formato gaussiano do tempo de hospitalização. Quem analisará os dados relatará as medidas descritivas mais adequadas. Ou, como mais frequentemente encontrado em publicações recentes, ele apresentará todas as medidas úteis para o leitor conseguir interpretá-las.#### O que acontece se a distribuição não for normal?Vamos repetir a **Figura 1**, mas olhando a distribuição de idades por grupo.```{r}library(ggplot2)summary_by_group <-aggregate(df$age, list(df$group), FUN = summary)sd_by_group <-aggregate(df$age, list(df$group), FUN = sd)mean_sd <-data.frame(summary_by_group$x[, "Mean"], sd_by_group)mean_int <-mean(df$age[df$group =="Intervention"])sd_int <-sd(df$age[df$group =="Intervention"])int_upper <- mean_int + (2*sd_int)int_bottom <- mean_int - (2*sd_int)mean_control <-mean(df$age[df$group =="Placebo"])sd_control <-sd(df$age[df$group =="Placebo"])control_upper <- mean_control + (2*sd_control)control_bottom <- mean_control - (2*sd_control)ggplot(df, aes(x = group, y = age, colour = group)) +geom_dotplot(binaxis="y", stackdir="down", dotsize =0.35, binwidth =2.0) +ylab("Idade no momento da randomização") +xlab("Grupo") +scale_y_continuous(breaks =seq(10, 110, by =10)) +geom_segment(aes(y = int_upper, yend = int_upper, x =0.5, xend =1.25), inherit.aes =FALSE) +geom_segment(aes(y = int_bottom, yend = int_bottom, x =0.5, xend =1.25), inherit.aes =FALSE) +geom_segment(aes(y = control_upper, yend = control_upper, x =1.5, xend =2.25), inherit.aes =FALSE) +geom_segment(aes(y = control_bottom, yend = control_bottom, x =1.5, xend =2.25), inherit.aes =FALSE) +theme_minimal() +theme(legend.position="none")```**Figura 2**. Distribuição de valores de idade nos dois gruposA **Figura 2** mostra a distribuição de idades nos dois grupos. Perceba que a distribuição de idades não é normal. A distribuição de idades é assimétrica, pois o estudo não incluiu participantes com menos de 18 anos e com mais de 90 anos.Apesar de não ser completamente incorreto pensar que "a maior parte dos dados está entre dois desvios-padrão da média de idade", fica claro que a regra geral do desvio-padrão não é a forma mais adequada para descrever a distribuição de idade. Aqui, um bom pesquisador daria ênfase a medidas como os quartis e a mediana.